
Snel antwoord op je data-vragen? Text-to-SQL is de (AI-)oplossing [stappenplan]

![Snel antwoord op je data-vragen? Text-to-SQL is de (AI-)oplossing [stappenplan]](https://www.frankwatching.com/app/uploads/2024/10/Robot-met-big-data-op-zijn-hoofd-bij-artikel-over-Text-to-SQL-1600x700.jpg)
Binnen je bedrijf heb je toegang tot data uit systemen zoals je e-commerce-shop, ERP of Google Analytics. Maar vaak ben je beperkt tot de standaard rapportages om inzichten uit deze data te halen. Stel je voor dat je simpelweg een vraag in gewonemensentaal aan je data zou kunnen stellen en direct een helder antwoord krijgt. In dit artikel deel ik hoe je een AI-oplossing kunt opzetten met Text-to-SQL om je data nog beter te kunnen verkennen.
Wat is Text-to-SQL?
Text-to-SQL is een technologie die gebruikmaakt van natuurlijke taalverwerking (NLP) en kunstmatige intelligentie (AI) om vragen in gewonemensentaal om te zetten in database taal (SQL-query’s). Met andere woorden, hiermee kun je simpelweg een vraag te stellen over je data, en het Text-to-SQL AI-model vertaalt die vraag naar een technische SQL-query die vervolgens de database bevraagt.
Denk aan vragen zoals:
- “Hoeveel omzet hebben we gedraaid in april vorig jaar?”
- “Wat is de gemiddelde review score van product [x] per jaar?”
- “Toon de omzet per winkel voor productgroep [x] over de afgelopen weken.”
Traditioneel zouden deze vragen handmatig moeten worden omgezet naar SQL-code, iets dat technische kennis en ervaring vereist. Met Text-to-SQL kunnen zelfs niet-technische gebruikers snel en gemakkelijk toegang krijgen tot waardevolle data-inzichten.
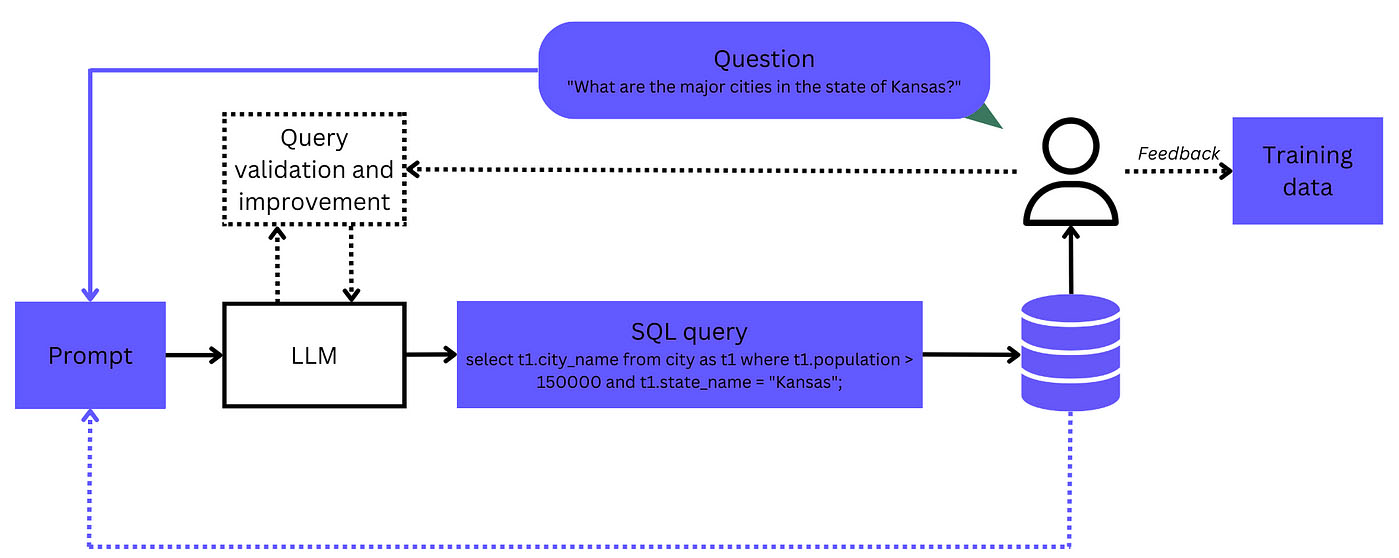
De werking van een Text-to-SQL-model. Klik op de afbeelding voor een grotere versie.
Wat zijn de voordelen van Text-to-SQL?
Voor professionals die in de data werken is het bekend dat Text-to-SQL een echte game changer is. De meeste enterprise bedrijven (zoals Pinterest) gebruiken deze techniek al enige tijd. Met de komst van open source AI is deze technologie nu ook beschikbaar voor het MKB.
1. Toegankelijkheid voor niet-technische gebruikers
Een van de grootste voordelen van Text-to-SQL is dat het databases toegankelijk maakt voor iedereen. Medewerkers die geen ervaring hebben met programmeertalen of SQL kunnen met deze technologie toch belangrijke data-inzichten verkrijgen zonder de tussenkomst van een data-analist.
2. Doorbreken van data silo’s
In veel bedrijven bevindt data zich in zogenaamde data silo’s: geïsoleerde systemen of afdelingen die hun eigen data beheren, zonder onderlinge koppelingen of uitwisseling. Dit kan de toegang tot waardevolle informatie belemmeren en samenwerking tussen teams vertragen.
Door AI-oplossingen zoals Text-to-SQL in te zetten, kunnen deze silo’s doorbroken worden. Je krijgt de mogelijkheid om data uit verschillende bronnen te combineren en te analyseren. Dit zorgt voor een meer holistisch beeld van je bedrijfsinformatie, wat betere, snellere en complexere besluitvorming mogelijk maakt.

3. Toegang tot complexe analyses
Text-to-SQL-modellen maken het mogelijk om zelf complexe data-analyses met meerdere databases, tabellen en geavanceerde bewerkingen te doen. Normaliter zou dit erg complex zijn vanwege geïsoleerde data en de complexiteit van de benodigde SQL.
Denk bijvoorbeeld aan vragen als: “Van de mannen die in 2024 product [x] bij ons kochten en de klantenservice-pagina bekeken, hoeveel plaatsten een review op Trustpilot en met welke score?”.
Deze vraag combineert e-commerce-data met Trustpilot-data en Google Analytics 4-data. Juist dit soort verbanden kunnen extreem waardevolle inzichten opleveren die in een normale rapportage niet te vinden zijn.
4. Bespaart tijd en verhoogt productiviteit
Met Text-to-SQL hoef je geen (complexe) SQL-query’s meer te schrijven of tijd te besteden aan het handmatig doorzoeken van data. Dit betekent dat je sneller antwoorden kunt krijgen, waardoor je productiviteit en efficiëntie toenemen.
Aandachtspunten bij Text-to-SQL
Maar wat zijn de aandachtspunten van Text-to-SQL? Allereerst is het belangrijk om te realiseren dat er meestal een publiek AI-model (zoals ChatGPT) wordt gebruikt en dat je dus riskeert om data naar derde partijen te lekken. Modellen zoals Vanna.ai hebben hier ingebouwde protectie voor, en daarnaast kan je met een business-account bij OpenAI ervoor zorgen dat je data GDPR-proof wordt verwerkt. Implementeer daarom niet zomaar een provider en onderzoek goed hoe dit wettelijk en technisch geregeld is.

Daarnaast is het belangrijk om te realiseren dat ook een AI-model fouten kan maken. Helemaal aan het begin. Als er nog weinig bevestigde trainingsdata is om de betrouwbaarheid aan te toetsen, kan het voorkomen dat er SQL-queries worden gegenereerd die niet kloppen. Dit is slecht controleerbaar door de niet-technische personen die de vraag intoetsen. Daarom is het belangrijk om eerst een hoge zekerheidsgraad op te bouwen met je model en om de vragen helder te stellen. Ook is het handig om aan het begin iemand met SQL-kennis alles goed te laten controleren voordat de antwoorden als waarheid worden aangenomen.
Tot slot is het belangrijk om te realiseren dat het zogenaamde ‘crap in, crap out’-principe geldt. Als de kwaliteit van je data niet goed is, zal ook een AI-model moeite hebben om een betrouwbaar antwoord te formuleren.
Hoe begin je met Text-to-SQL?
Text-to-SQL kan je op verschillende manieren opzetten. Je kan het model direct aansluiten op 1 dataset. Of je kan deze aansluiten op een datawarehouse, zodat je diverse silo’s kan combineren in complexere analyses. Een mogelijke opzet die ik zelf vaak hanteer is eentje in Google Cloud die geavanceerde analyses toestaat.
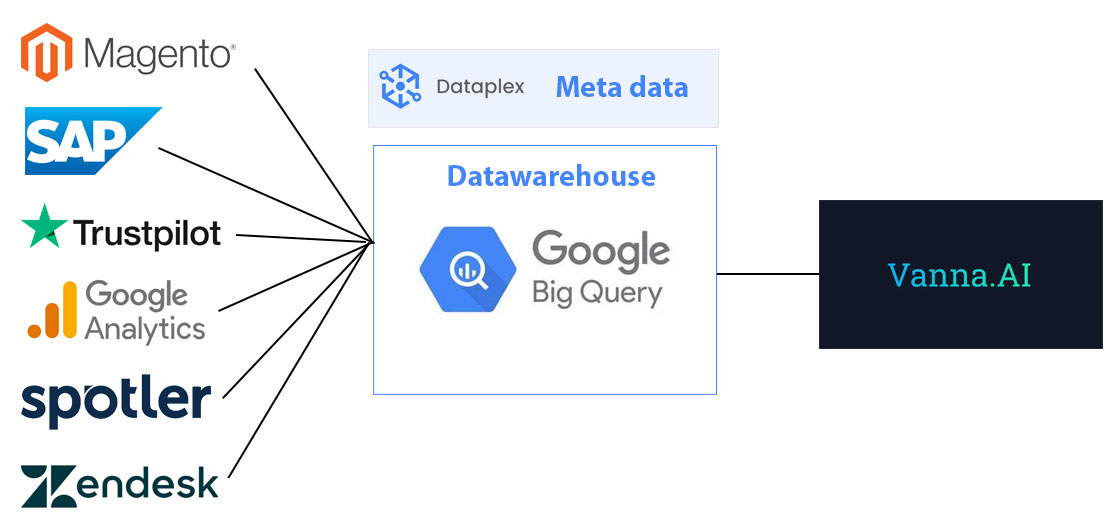
Stap 0. Basisbeginselen: de data-setup
Allereerst heb je toegang tot je data nodig. Hiervoor zetten organisaties vaak een datawarehouse op waarbij alle data uit de verschillende bronnen in 1 verzamelbak is gestoken. Een betaalbare oplossing voor een datawarehouse is Google BigQuery. Voor tal van bronnen, zoals Google Analytics 4, Facebook, en Google Ads, bestaat er al een standaard integratie die zorgt dat je data centraal op 1 plek terecht komt. Voor je e-commerce systeem of andere bronnen dien je zelf de data naar BigQuery te sturen door bijvoorbeeld een webhook, API-integratie of database-replicatie.
Zorg ervoor dat je data-kwaliteit voldoende is. Als de data geheel ongestructureerd en onbegrijpbaar in je database zit, zal ook een Text-to-SQL problemen hebben hier iets zinnigs uit te halen. Master data management is dus key.
Stap 1. Voeg meta-data toe aan je datasets
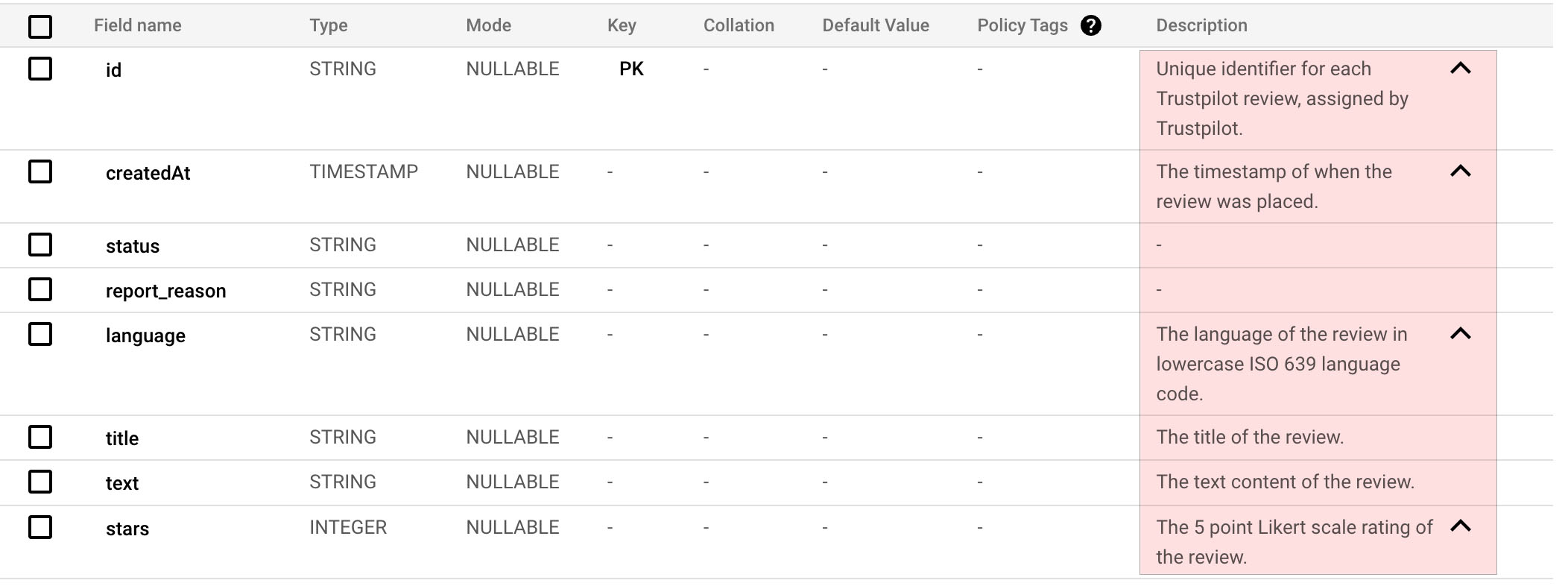
Zodra al je data in je warehouse zit, zorg je ervoor dat de kwaliteit van de data op orde is. Daarbij hoort ook het beschrijven van de dataset door middel van meta-data. Wat je doet is voor iedere tabel en kolom in mensentaal uitleggen wat de kolom precies omvat. En welke waardes of nuances daarbij horen. Op die manier heeft je AI-model straks net wat meer informatie over hoe je data werkt. Hieronder zie je bijvoorbeeld de omschrijving van de kolommen in een Trustpilot-review dataset in BigQuery. Klik op de afbeelding voor een grotere versie.
Stap 2. Ontwikkel en train je Text-to-SQL-model
Er zijn verschillende websites die Text-to-SQL als service aanbieden. Daarnaast zijn analyse-pakketten zoals PowerBi en Google Looker druk bezig om dit soort features in private beta uit te rollen. Wachten is echter niet nodig. Hieronder bespreek ik hoe je aan de slag kunt met Vanna.ai, beschikbaar als service-platform in betaalde versie of als gratis open source-versie. Zelf kies ik voor Vanna.ai vanwege het open source-karakter en de goede prestaties die het model leverde toen ik een tool-selectie deed.

Vanna.ai Open Source maakt het mogelijk om eenvoudig een Text-to-SQL-systeem te implementeren en te gebruiken binnen je organisatie. Hier zijn de stappen om te beginnen met Vanna.ai.
Betaalde cloud-versie
- Ga naar de website van Vanna.ai en maak een account aan. Het platform biedt een gebruiksvriendelijke interface waarmee je meteen aan de slag kunt.
- Zodra je bent ingelogd, kun je je database(s) koppelen. Vanna.ai ondersteunt verschillende typen databases, waaronder MySQL, BigQuery, PostgreSQL, en SQL Server.
- Vanna.ai gebruikt grote taalmodellen (LLM’s) om natuurlijke taalvragen te vertalen naar SQL-query’s. Je kunt het model trainen of afstemmen op de specifieke behoeften van je database door de structuur van je data en de terminologie (meta-data) van je bedrijf te importeren als trainingsdata.
Gratis open source-versie
Laat je developer een Jupiter Notebook opzetten of installeer het Vanna Python package op een server. Je kan daarna je eigen Python-code ontwikkelen die het Vanna.ai-model traint op jouw data-situatie. In mijn geval train ik het model met de volgende data die ik via Python ophaal uit diverse APIs:
- DDL-statements die automatisch uit BigQuery worden gehaald.
- Een samenvatting van alle BigQuery-datasets die ik wil voeren aan het model. Dit beheer ik door middel van tags in Google Dataplex.
- Aangezien de DDL-statement in BigQuery geen primary- en foreign key relations kent, voeg ik deze via een maatwerk-query ook toe.
- Algemene documentatie die ik in Google Doc en Dataplex beheer. Hierbij train ik het model om onze definitie van businesstermen te begrijpen, maar ook andere relevante informatie die belangrijk kan zijn voor het begrijpen van de data.
Stap 3. Stel je vragen in natuurlijke taal
Nu komt het leuke gedeelte! Je kunt beginnen met het stellen van vragen zoals:
- “Welke producten hebben we de afgelopen maand verkocht aan alle mannen in ons klantbestand?”
- “Hoeveel nieuwe klanten hebben we in 2024, die meer dan 2 aankopen deden?”
Vanna.ai genereert automatisch de juiste SQL-query, haalt de data op, en presenteert het resultaat overzichtelijk.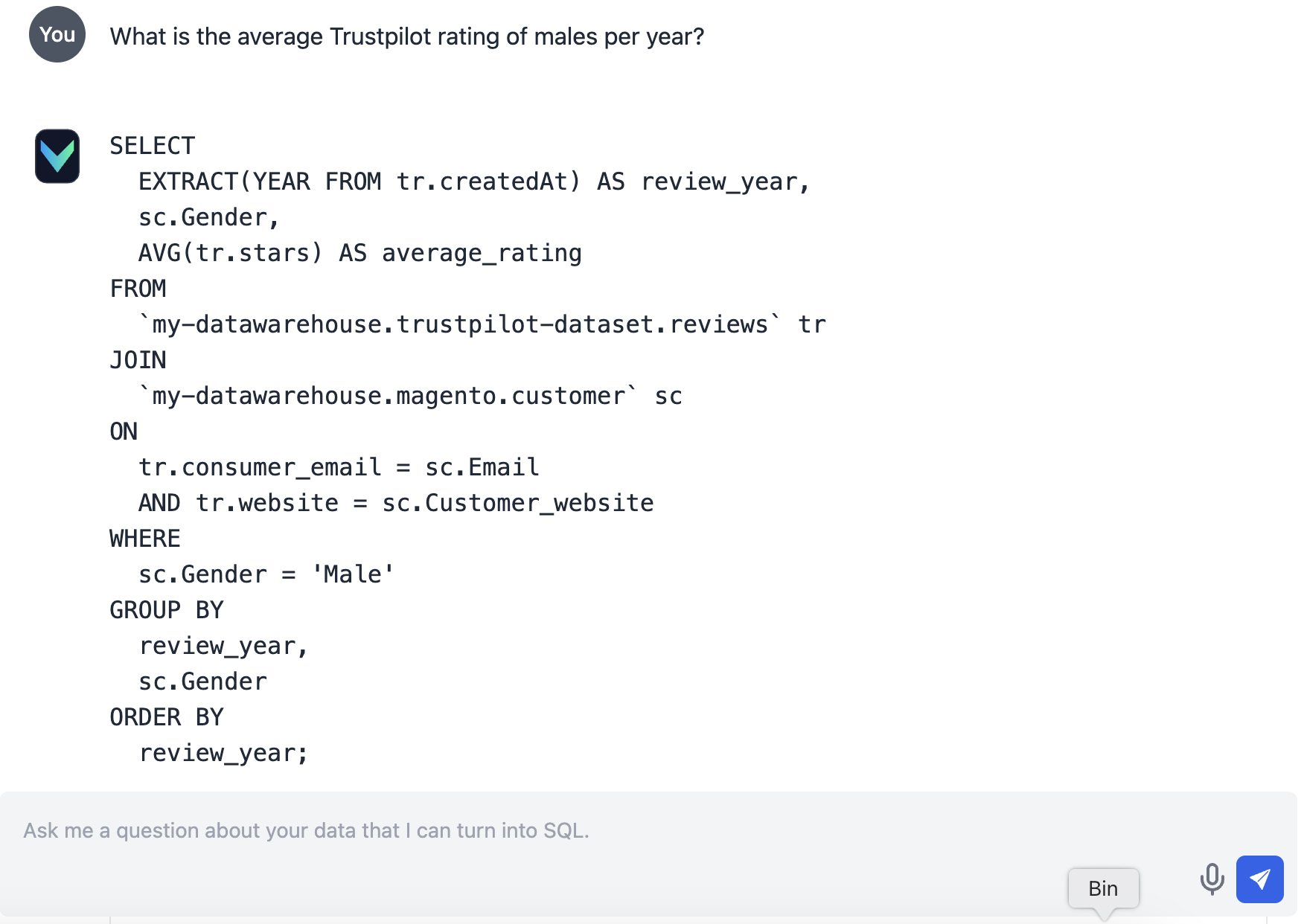
Stap 4. Analyseer de resultaten
De resultaten van je query worden gepresenteerd in een gemakkelijk te begrijpen formaat. Je kunt deze resultaten verder analyseren of exporteren naar andere tools voor rapportage of visualisatie. Daarnaast kan je vervolgvragen stellen om de data verder te verfijnen. Eveneens kan je direct een grafiek genereren voor bijvoorbeeld een Powerpoint-presentatie. En tot slot kan je het model verder trainen door aan te geven of het gegenereerde resultaat klopt met de vraag die je stelde. Op die manier wordt het model steeds slimmer!
Bruikbare inzichten voor iedereen
Wat ooit voorbehouden was aan data-experts, is nu beschikbaar voor iedereen in je organisatie, ongeacht technische vaardigheden. Het is dus tijd om je datastrategie op orde te brengen.
Sommige afbeeldingen in dit artikel zijn gemaakt met Flux op Replicate.com.
Over de auteur