
Zoekwoordenonderzoek automatiseren? Cluster eenvoudig keywords met Python

Het meest tijdrovende onderdeel van ons vak als SEO-specialist blijft het uitvoeren van een zoekwoordenonderzoek. Bijna iedere SEO-strategie begint ermee, maar ook tijdens het proces blijft het onderzoeken van het organische speelveld een must. Echter, als we kijken naar de praktijk komt het maar zelden voor dat we echt de benodigde tijd krijgen om alles secuur te doen. Dat moet makkelijker kunnen, toch?
Gelukkig is het zoekwoordenonderzoek een onderdeel waar we veel van kunnen automatiseren om ons werk makkelijker en datagedreven te maken. Zo kan Python ons helpen met het bepalen van welke keywords bij elkaar passen zodat we deze kunnen clusteren. Ik leg je uit hoe dit precies in zijn werk gaat en aan het eind van het artikel geef ik je de code in een Google Colab zodat je deze zelf kunt gebruiken.
Clusteren van keywords, een grootse tijddoder
Na het opmaken van een longlist komt het grootste onderdeel van een zoekwoordenonderzoek om de hoek kijken: het samenvoegen van deze keywords om ervoor te zorgen dat het duidelijk is welke keywords je samen kunt voegen om een zo compleet mogelijk pagina op te bouwen. Maar ook om kannibalisme te voorkomen, blijft clusteren een essentieel onderdeel.
Je kunt het bijna niet goed doen
Het handmatig doorlopen van deze lijst kost echter veel tijd, waarbij je ook vaak nog genoodzaakt bent om dit vanuit je eigen expertise te doen. Eindresultaat: keywords geclusterd op basis van eigen expertise, zonder dat je weet of dit wel echt aansluit bij het zoekgedrag van mensen in zoekmachines. Controleer je dit laatste wel, dan krijg je jouw opdrachtgever of leidinggevende op je dak, omdat er immens veel tijd in is gaan zitten.
Zowel andere vakgenoten als ikzelf zijn al meerdere malen in de praktijk tegen dit probleem aangelopen. Dit bracht mij aan het denken. Wat als je op basis van een database kan bepalen welke keywords wel of niet bij elkaar horen en dit in een bulk kunt samenvoegen?
Het belang van datagedreven clusteren op basis van de SERP-similarity
De overeenkomst van de zoekresultatenpagina geeft een sterk signaal wanneer twee keywords dezelfde zoekintentie hebben. Het algoritme van Google is dusdanig ontwikkeld dat, wanneer gebruikers zoeken op het keyword ‘fiets’, ze een zoekresultatenpagina met producten te zien krijgen en we de conclusie kunnen trekken dat hier een koopgerichte zoekintentie achter zit.
Als je vervolgens het keyword ‘fiets’ vergelijkt met ‘fiets kopen’, wordt snel duidelijk dat deze keywords een grote overlap hebben. Deze overlap vertelt eigenlijk dat het verstandig is om beide keywords te gebruiken op een pagina waar fietsen te koop zijn. Oftewel, deze organische resultaten bieden een mooie databron om de overlap tussen verschillende keywords te bepalen.
Wanneer we zoekresultaten van meerdere keywords met elkaar vergelijken, kunnen we snel en datagedreven achterhalen welke keywords overlap hebben. Deze keywords kun je op één pagina samenvoegen.
Automatisch keywords clusteren met Python
Middels de programmeertaal Python kun je eenvoudig de bovengenoemde situatie automatiseren. Python is namelijk in staat snel data te verzamelen van de zoekresultaten vanuit de SERP (met behulp van de juiste API). Deze gegevens kan Python vervolgens vergelijken met de andere keywords om zo keywords met overlap samen te voegen.
Gelukkig voor jou heb ik dit script al gebouwd en kun je hier eenvoudig gebruik van maken. Hieronder leg ik per onderdeel uit wat het script precies doet, maar wil je hier niet op wachten? Dan kun je direct naar de Google Colab gaan, zodat je eenvoudig zelf gebruik kunt maken van het script zonder dat je hier de technische kennis van hoeft te hebben.

Zoekresultaten achterhalen met een API
Om te beginnen moeten we van de lijst met keywords de huidige zoekresultaten achterhalen. Er zijn verschillende API’s die hierbij kunnen helpen. Het zelf scrapen van de zoekresultatenpagina is namelijk vrij complex met Python. Zeker gezien de kosten van deze API’s relatief laag zijn, en de werking een stuk betrouwbaarder is, is dit de beste keuze.
In mijn voorbeeld maak ik gebruik van de API van SerpAPI. Deze kent een gratis trial tot honderd zoekopdrachten en is daarna betaald. De kosten haal je er makkelijk uit wanneer je erachter komt hoeveel tijd dit bespaart in de praktijk.
Je kunt ervoor kiezen een andere API te gebruiken of toch zelf de zoekresultaten te gaan scrapen. Ook dan kun je gewoon de rest van het script gebruiken, het eerste deel zul je dan wel moeten herschrijven.
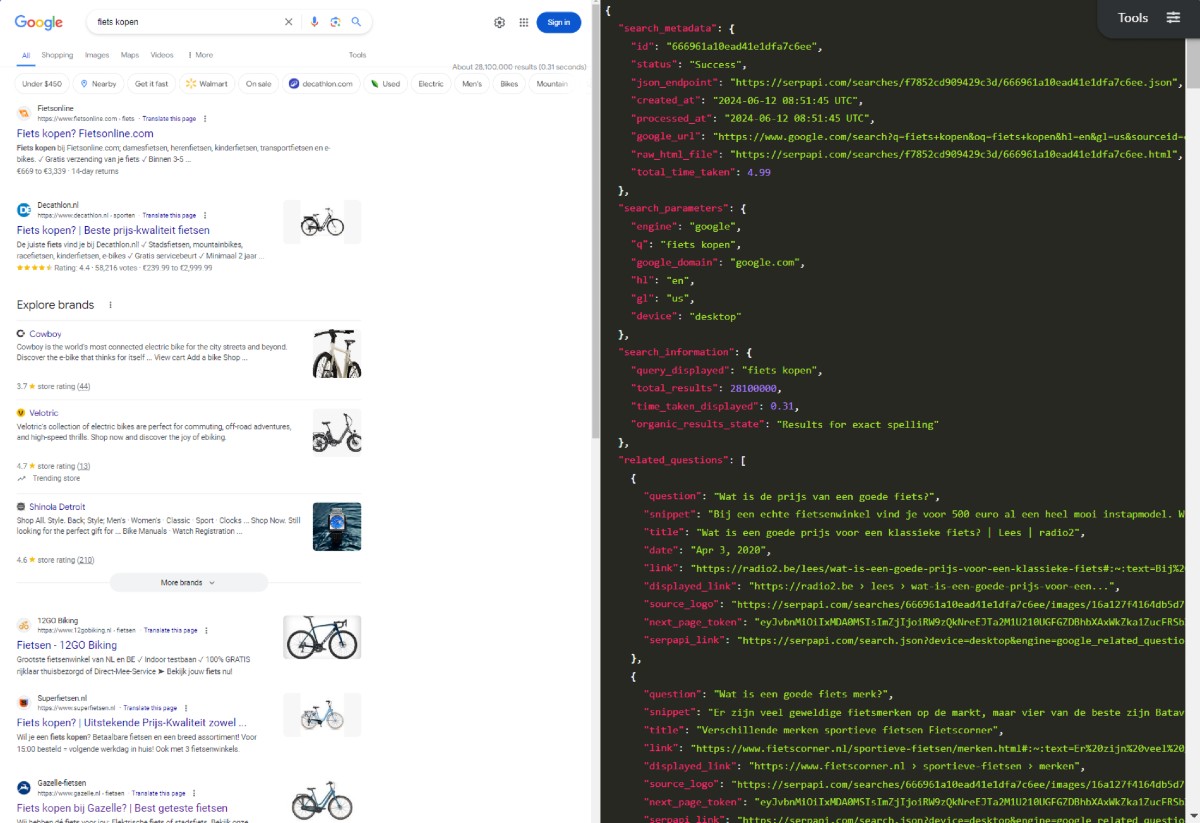
Data vergelijken en bundelen
De binnengekomen data uit de API wordt vervolgens omgezet tot tien links per keyword. Dit zijn de tien links van de organische resultaten van de zoekresultaten van het keyword. Vervolgens vergelijkt het script de resultaten van deze keywords. Wanneer er een overlap is, worden deze in een aparte dictionary samengevoegd.
Op basis van drie overeenkomende resultaten worden de keywords samengevoegd. In de praktijk zie je dat er geen ‘one fits all’ is als het gaat om dit getal. In sommige branches kun je namelijk beter clusteren op basis van vier overeenkomende URL’s, terwijl dit in andere branches juist met twee overeenkomende URL’s betere resultaten oplevert.
Mooie basis maar nog niet volledig accuraat
Het laatste wat je moet weten van het script voordat je er mee aan de slag kan, is dat het een goede basis vormt. Volledig accuraat is het niet. Er zullen keywords tussen zitten die je wellicht toch liever gaat samenvoegen of juist los moet trekken op een aparte pagina. De afhankelijkheid die we als SEO-specialisten hebben van Google geldt ook hiervoor. Als de zoekresultaten niet ideaal zijn, heeft dit script een verkeerde databron en zullen de resultaten niet optimaal zijn.
Echter, je gaat merken dat je met dit script uren aan tijd zal besparen tijdens ieder zoekwoordenonderzoek. Zeker als je met duizenden keywords werkt die snel geclusterd moeten worden, ga je merken hoe fijn deze werkwijze is.
Ga aan de slag met het script
In deze Google Colab vind je het script waardoor je eenvoudig online keywords kunt clusteren. Voeg zelf je API-key vanuit SerpAPI toe op de aangewezen plek om ervoor te zorgen dat je gebruik kunt maken van de API. Het Excel-bestand dat je uploadt zal vervolgens geclusterd worden en in je downloadmap verschijnen. Nu heb je een Excel-bestand met keywords die op een datagedreven manier geclusterd zijn. Succes met het clusteren van jouw keywords!
Over de auteur