Hoe meet je succesvol het sentiment op social media?


Is er een toekomst voor tools die social media monitoren? Een interessante vraag die ik online tegenkwam. Socialmedia-platformen wijzigen namelijk steeds hun API’s en verwijderen meetmogelijkheden. Zo bevat de beperkte Instagram-data die je nog kunt binnenhalen geen metrics meer zoals likes, bereik en engagement. Wat heb je dan nog aan een monitoringtool?
Column – We moeten het meten van social media dus eigenlijk over een andere boeg gaan gooien. Bijvoorbeeld door ons meer te focussen op het meten van sentiment. Een sentimentanalyse houdt in dat je analyseert of berichten positief, neutraal of negatief zijn. Dit gaat dus echt om de inhoud van een post.
En een reactie, mening of review geeft ook meer inzicht dan ‘een like’: een van de redenen waarom Instagram de likes misschien gaat verwijderen. Een sentimentalanyse klinkt dus als een goed idee, maar is ingewikkelder dan het lijkt.
Je analyseert woorden, geen betekenis.
Hoe negatief is negatief sentiment?
Veel grote merken, die enorm veel berichten binnenkrijgen, zetten de automatische sentimentanalyse in om de urgentie van een bericht aan te geven. Vaak wordt dan de nadruk gelegd op negatieve berichten. Met het idee dat je negatieve berichten snel moet behandelen om verdere schade te voorkomen. Klinkt als een goed plan, maar wetenschappelijk onderzoek laat zien dat negatieve berichtgeving niet per se ‘belangrijker’ is. Juist ook het reageren op positieve of neutrale berichten kan sterk positieve effecten opleveren.
Daarnaast heeft onderzoek aangetoond dat online sentiment kan verschillen van ‘offline sentiment’ (de reactie in de echte wereld). Online berichten zijn vaak extremer en er kan een andere motivatie achter zitten. Ook is het zo dat mensen eerder iets negatiefs delen dan iets positiefs. En de belangrijkste reden om als bedrijf niet direct in de kramp te schieten bij veel negatief sentiment: de meting zelf is niet altijd betrouwbaar.
De uitdagingen bij automatische analyse
Bij Frankwatching hebben we een monitoringtool, maar we gebruiken de (automatische) sentimentanalyse nog niet heel intensief. Ik dook er voor dit artikel in.
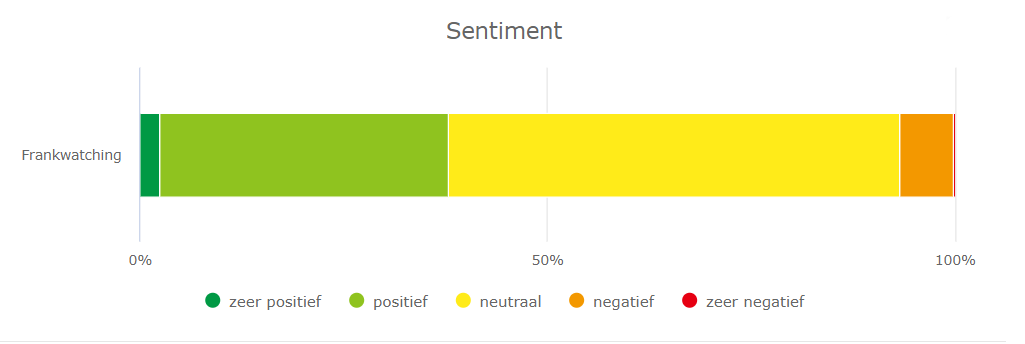
Als ik de resultaten filter en alleen de negatieve en zeer negatieve berichten laat weergeven, zie ik direct een probleem. Artikelen worden vaak gedeeld aan de hand van de titel van het artikel. Artikelen met een negatief woord in de titel worden daardoor als ‘negatief’ bestempeld. Twee voorbeelden:
- Zo ontsnap je als merk aan de eenheidsworst
- Social media na je overlijden: to delete or not to delete?
De tool houdt er dus geen rekening mee dat dit een titel is van een artikel, en geen mening van iemand die dit deelt. Bij de selectie op positief sentiment gaat het precies op dezelfde manier mis. Kijk maar:
- 10x populair: socialmedia-trends, kantoorhonden & UX
- Merken op social media: dit vinden je volgers belangrijk
Het zou natuurlijk kunnen dat iemand deze post deelt omdat hij of zij hier positief over is. Maar als er verder geen mening in het bericht wordt gedeeld, zou ik deze berichten liever terugvinden in het segment ‘neutraal’.
Leren interpreteren
De context van een bericht is ook van belang. Stel, je krijgt de volgende twee korte reacties onder een Facebookpost binnen:
- ‘Alles’
- ‘Helemaal niks!’
Je zou zeggen dat de eerste positief is en de tweede negatief. Maar wat nou als dit twee antwoorden zijn op de vraag: ‘Wat kan er de volgende keer beter bij ons event?’. Dan verandert de betekenis ineens. De analysetool en/of medewerker zou deze informatie dus moeten meenemen in de kwalificatie.
Objectieve vs. subjectieve meting
Je hebt grofweg 2 verschillende vormen van sentimentanalyse: geautomatiseerd en handmatig. Oftewel, objectief en subjectief.
1. Objectieve meting
Een standaard geautomatiseerde sentimentanalyse wordt gebaseerd op een lijst met Nederlandse woorden en woordcombinaties. Met woordcombinaties wordt dan bijvoorbeeld ‘niet goed’ bedoeld. Het woord ‘goed’ is natuurlijk positief, maar in combinatie met ‘niet’ is het negatief.
Kortweg kun je een geautomatiseerde sentimentanalyse op drie manieren inrichten:
- Rule-based: het sentiment wordt gebaseerd op handmatig ingestelde regels
- Automatic: het systeem bepaalt het sentiment met behulp van machine learning
- Hybrid: een combinatie van de twee bovenstaande
Maar ook al kies je voor de gecombineerde Hybrid-versie: een geautomatiseerde sentimentanalyse houdt geen rekening met dubbele ontkenningen, sarcasme, ironie, emoticons, cynisme en vergelijkingen. Daarnaast hebben woorden in straattaal of jongerentaal soms een andere betekenis, zoals ‘wreed’ of ‘ziek’. Deze woorden kunnen zowel negatief als positief worden gebruikt. Hier worden overigens wel steeds meer experimenten mee gedaan. Zoals dit experiment met Netflix-reviews, waarin verschillende emoties in tekst steeds beter worden herkend.
Geautomatiseerde sentimentanalyse kan dus een grove schatting maken over of een bericht positief, neutraal of negatief is. Maar het heeft ook beperkingen.
2. Subjectieve meting
Bij een handmatige sentimentanalyse bepaalt een medewerker of een bericht positief of negatief is. Dubbele ontkenningen, emoticons en vergelijkingen op de juiste manier interpreteren is geen probleem.
Maar sarcasme, ironie en humor zijn ook voor een mens lastig te beoordelen door de afwezigheid van face-to-facecontact. Je kunt natuurlijk niet zien of iemand met z’n ogen rolt, stem verheft of met z’n armen over elkaar staat. Daarnaast interpreteren verschillende personen in verschillende situaties berichten op verschillende manieren.

Maar, wat nu?
Alle berichten handmatig classificeren? Dat is niet te doen. Alleen automatische sentimentanalyse? Daar kun je geen goede conclusies uit trekken. Een combinatie van deze twee kan de uitkomst kunnen bieden, maar is ook niet zaligmakend. Voor nu is het in ieder geval een goed idee om, als je de capaciteit ervoor hebt, de automatische en handmatige meting te combineren en je niet alleen te focussen op het negatieve sentiment.
Hoe lang zal het nog duren voordat er een systeem op de markt komt dat het sentiment (ook van bijvoorbeeld video’s, audio, afbeeldingen en emoticons) wel 100 procent goed interpreteert? Of is dit een proces wat een systeem of robot nooit helemaal van de mens zal kunnen overnemen?
Over de auteur
