 ChatGPT
ChatGPT Haal meerwaarde uit je first-party data met machine learning: 4 praktische voorbeelden


Artificial Intelligence en het wegvallen van veel third party data heeft en zal grote invloed hebben op onze toekomst als marketeers. Toch zijn er naast de techgiganten (Google, Facebook, Amazon, Microsoft) nog maar weinig bedrijven die AI en machine learning gebruiken om meerwaarde te halen uit hun eigen website of CRM-data. Dit zal in de toekomst juist hét punt gaan worden waar je concurrentievoordeel mee kunt behalen.
Ik laat je graag zien hoe je als marketeer met behulp van machine learning meerwaarde uit je first-party data haalt.
First- en third-party data
Voor het aansturen van onze marketingcampagnes gebruiken we informatie die is verkregen uit verschillende cookies. Cookies op de eigen website zijn een vorm van first-party data. Het volgen van gebruikers op jouw website via een Facebook-cookie is een vorm van third-party data. Beide cookies worden steeds meer uitgebannen door bekende browsers als Safari en Firefox.
Als Google Chrome volgend jaar ook minder cookies gaat toestaan en de levensduur van cookies wordt verkort, ben je steeds meer toegewezen op je eigen first-party data. Daarom vertel ik je in dit artikel graag hoe je hier meer mee kunt doen.
Machine Learning
De eerste stap richting AI is machine learning. Machine learning is ontstaan in de zoektocht naar artificial intelligence (AI) en is op dit moment een stuk toegankelijker als je met jouw eigen datasets wilt werken. De focus van dit artikel ligt op het toepassen van wiskundige modellen op datasets oftewel: machine learning. Machine learning wordt in het marketingveld bijvoorbeeld ook in ingezet door Google voor het optimaliseren van smartbidding biedstrategieën binnen Google Ads.
De definitie machine Learning op Wikipedia:
Machine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions
Voor machine learning zijn grote datasets nodig om voorspellingen te doen. Datasets waar jij misschien al over beschikt. Voorspellingen zijn mogelijk zodra je een wiskundig model hebt getraind om te werken met deze dataset, en dat is makkelijker / bereikbaarder dan je (waarschijnlijk) denkt.
Wat is een grote, bruikbare dataset?
Bij een grote dataset moet je denken aan een tabel met tientallen kolommen en bijvoorbeeld honderden rijen. Het is niet te zeggen hoe groot een dataset moet zijn om er een model mee te kunnen trainen. Dit hangt namelijk zowel van de complexiteit van jouw ‘probleem’ als de complexiteit van jouw model af.
Voorbeeld machine learning: Wie overleeft de Titanic-ramp?
Zo is het mogelijk om op basis van de passagierslijst van de Titanic te voorspellen welke passagiers een grotere kans hadden om de ramp te overleven.
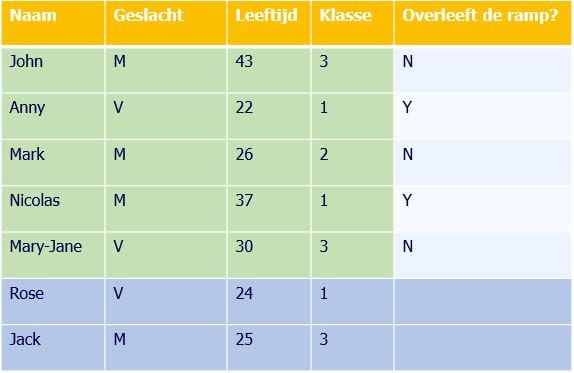
Deze dataset bevat input variabelen en de gewenste voorspelling die wij willen doen, namelijk of mensen de ramp kunnen overleven. De groene kolommen zijn de ‘input variabelen’. Of ze het hebben overleefd is de ‘gewenste uitkomst’.
Voorbeeld dataset: Passagiers Titanic
Wanneer jouw dataset groot genoeg is, kun je het model 70% van jouw data tonen inclusief de gewenste uitkomst. Dit noemen we de trainingsset. Hiermee leert het model dat je gebruikt welke variabelen de grootste invloed hadden op de overlevingskans.
In de bovenstaande tabel zijn op de verticale as de groene rijen de trainingset. Wanneer je nu de overige 30% van de dataset (blauwe rijen) aan jouw model ‘voert’ kan deze op basis van de input variabelen een voorspelling doen. Zo kunnen we bijvoorbeeld achterhalen wat de overlevingskans is van Rose en Jack.
Supervised Learning
Deze manier van leren noemen we supervised learning. Dit is vergelijkbaar met een baby die je plaatjes laat zien. Als je vaak genoeg vertelt dat een plaatje van een koe een koe is, gaat een baby dit op den duur ook zelf herkennen.
Maar hoe zet je supervised learning nu in voor marketingscampagnes? Aan de hand van 4 voorbeeldcases laat ik je zien hoe je je dataset verrijkt met machine learning. De uitkomsten kunnen naast doelgroepen ook andere waardevolle inzichten opleveren.
De vier praktische voorbeelden die volgen, betreffen de volgende onderwerpen:
- Conversiekans voorspellen op basis van E-commerce-data
- Klanten clusteren op basis van E-commerce- en CRM-data
- Churn voorspellen op basis van app data (SaaS bedrijf)
- Customer Lifetime Value voorspellen op basis van E-commerce-data
1. Conversiekans voorspellen op basis van e-commerce data met machine learning
Benodigd: e-commerce dataset inclusief unieke bezoeker-id’s.
Als jij jouw e-commerce-data goed geordend hebt, is het mogelijk om op basis hiervan voorspellingen te doen. Als jouw bezoekers individueel identificeerbaar zijn met een unieke code, kun je kijken welke acties op jouw website zijn ondernomen door gebruikers. Vervolgens kun je ook zien welke gebruikers de afgelopen periode een transactie hebben gedaan op de website.
Als jij deze data gebruikt om een model te trainen, zal deze de meest waardevolle acties identificeren (input variabelen) voor het behalen van een transactie (gewenste output).
Voorbeelden van zo’n actie:
- Tijd op de site;
- Het aantal pagina’s wat een bezoeker heeft bekeken;
- Of het aantal producten wat in een winkelmandje is gestopt.
Doelgroepen die je kunt aanmaken:
- Google Analytics: Doelgroep van websitegebruikers die een bepaalde hoeveelheid producten in hun winkelmandje hebben gestopt.
- Google Ads: Een similar audience van deze doelgroep.
Deze doelgroepen kunnen vervolgens worden gebruikt voor dynamische retargeting campagnes, waarbij je ze via Display de laatste producten uit hun winkelmandje laat zien. Ook kan je de doelgroep een hoger bod meegeven binnen Google Ads.
2. Klanten clusteren op basis van e-commerce en CRM-data
Om de volgende doelgroep aan te maken heb je een koppeling nodig tussen jouw CRM-systeem en e-commerce-data. Voor veel mensen is dit eigenlijk al de grootste uitdaging. Als je de data uit jouw CRM en e-commerce-systeem in een dataset hebt, kun je deze gaan analyseren. Hieronder leg ik uit hoe je waardevolle inzichten uit deze data kunt halen.
De inzichten
Er zijn wiskundige modellen die de verbanden tussen grote groepen datapunten herkennen. Deze modellen herkennen de datapuntgroepen met de kleinste onderlinge afstand. Zo kun je bijvoorbeeld klanten binnen jouw dataset clusteren die vaker dan gemiddeld producten retourneren.
Voorbeelden van relevante klantsegmenten:
- Relatief nieuwe websitegebruikers die nog niks besteld hebben maar veel interactie op de website vertonen;
- Klanten die al lang geen producten meer besteld hebben;
- Waardevolle klanten die veel interactie tonen op de site en regelmatig bestellen.
Doelgroep voorbeeld
Op basis van deze segmenten kun je een remarketing-campagne instellen. Deze campagne mikt op de heractivatie van de klanten die al lang niks meer besteld hebben. Een andere optie is om ze juist uit te sluiten. Dit is aan te raden wanneer je geen marketingbudget wilt steken in gebruikers waarvan de kans kleiner is dat ze gaan converteren.

3. Churn voorspellen op basis van app data (SaaS-bedrijf)
Stel je voor dat je een mobiele app beheert. In deze case wil je het aantal gebruikers dat jouw app verwijdert terugdringen.
Als jij een dataset hebt met uniek identificeerbare gebruikers en hun in-app-acties is het mogelijk om voorspellingen te doen over de kans dat gebruikers de app verwijderen (of niet actief gebruiken).
Gebruik bijvoorbeeld een dataset van drie maanden die ook laat zien of gebruikers de app hebben verwijderd en geef vervolgens in een dataset de kolom ‘app verwijderd’ als voorspelbare waarde aan. Train nu je model met een set van je data. Jouw model leert zo welke variabelen de kans op het verwijderen van de app verhogen.
Misschien leer je dat gebruikers die de eerste maand vijf spelletjes spelen de app de eerste drie maanden niet verwijderen. Om de churn te beperken besluit je op basis van deze learnings om gebruikers na het spelen van vijf spellen te belonen met een leuke extra.
Doelgroep:
Gebruikers die na drie maanden nog geen vijf spelletjes hebben gespeeld, plaats je in een doelgroep. Deze doelgroep moedig je via een display of in-app-campagne aan om de app weer eens te gebruiken.
4. Customer Lifetime Value (CLTV) voorspellen op basis van e-commerce data
De wens van iedere marketeer: je campagnes optimaliseren voor waardevolle klanten.
Heb je e-commerce-data verzameld over een langere periode, dan weet je welke acties je gebruikers ondernemen en hoeveel ze bij jou op de site bestellen. Op basis van deze data kun je voorspellingen doen over hun uitgavenpatroon in de komende periode. Zo kun je de klantwaarde berekenen.
Hier gebruik je weer het principe van supervised learning. Je gebruikt namelijk een oude dataset met daarin klantinteracties en de opbrengst over een bepaalde periode om jouw model te trainen. Vervolgens kan het model voorspellingen gaan maken over de verwachte opbrengst in de toekomst.
Welke doelgroepen maak je hiermee?
- Google Analytics: Doelgroep van je meest waardevolle klanten. Deze zou je een speciale aanbieding kunnen doen via de mail. Of je zou ze op een speciale actie-landingspagina kunnen laten landen.
- Google Ads: Lookalikes van je meest en minst waardevolle klanten. Op deze doelgroepen zou je op en af kunnen bieden.
Zelf aan de slag?
Heeft dit artikel jou geïnteresseerd in de mogelijkheden van AI en machine learning voor jouw campagnes? Je kunt zelf de tools gaan ontdekken. Zo gebruikte ik Orange en Dataiku, die beide gratis versies aanbieden om wiskundige modellen te trainen. Orange biedt ook een gebruiksvriendelijke onboarding inclusief filmpjes.
Over de auteur




